구글, MS, 네이버, 다음 등에서 한영 번역 API를 제공하기는 하나.. 싸지 않다.
무료 quota는 너무 적어서 맛 보기 정도만 가능.
비싸
네이버 요금 체계, 정산 시스템에 대한 비판글은 다른 글로 좀더 자세히 적어 볼 생각
그래서 직접 학습 시켜서 하나 만들면 어떨까 생각해 봄.
모델을 만들 능력은 안되고,
"공개된 모델에 데이터 허브에서 받은 데이터로 학습시키면 되지 않을까?"
라는 순진한 생각으로 지옥문을 열어 버림.
모델은 너로 정했다.
https://github.com/seujung/KoBART-translation
GitHub - seujung/KoBART-translation
Contribute to seujung/KoBART-translation development by creating an account on GitHub.
github.com
요즘은 트랜스포머가 대세이긴 한데... 이걸로 먼저 해 보고.. 잘 되면 트랜스포머로 다시 메뚜기 뛰면 되지 머. 인생 뭐 있간디.
KoBART 설치
conda create -n kobart python=3.9
conda activate kobart
pip install git+https://github.com/SKT-AI/KoBART#egg=kobart
이렇게 하면, kobart가 pip 패키지 처럼 설치된다.

얘는 문장에서 형태소 분리하는 녀석인 것 같은데?
학습된 모델(preTrained data)은 코드를 실행시키면 자동으로 받는 것 같고...
어떻게 쓰는 녀석인지 함 돌려보는 것이 인지상정!
아래와 같은 내용을 담은 파이썬 파일 생성. 공식 제공하는 샘플의 내용의 무지성 복사 + 약간의 유두리.
from transformers import BartModel
from kobart import get_pytorch_kobart_model, get_kobart_tokenizer
kobart_tokenizer = get_kobart_tokenizer()
model = BartModel.from_pretrained(get_pytorch_kobart_model())
inputs = kobart_tokenizer(['안녕하세요.'], return_tensors='pt')
model(inputs['input_ids'])
ret=kobart_tokenizer.tokenize("와떠르 게떠르 쉐떠르 뻑. 뭔소리고?")
print(ret)
이것은 실행 결과
(kobart) whyun@k8s-worker-node14:~/workspace/KoB$ !p
python kobart_test.py
using cached model. /home/whyun/workspace/KoB/.cache/kobart_base_tokenizer_cased_cf74400bce.zip
using cached model. /home/whyun/workspace/KoB/.cache/kobart_base_cased_ff4bda5738.zip
['▁와', '떠', '르', '▁게', '떠', '르', '▁쉐', '떠', '르', '▁', '뻑', '.', '▁뭔', '소', '리고', '?']
실행시킨 디렉토리의 .cache 파일을 보면 다음과 같다.

흠.. 여기까진 오케이!
번역 기능을 위한 KoBART-translation 인공지능 학습 코드를 다운 받자.
https://github.com/seujung/KoBART-translation
GitHub - seujung/KoBART-translation
Contribute to seujung/KoBART-translation development by creating an account on GitHub.
github.com
git clone https://github.com/seujung/KoBART-translation.git
pip install -r requirements.txt
어라? 왠 에러?
(kobart) whyun@k8s-worker-node14:~/workspace/KoBART-translation$ !pi
pip install -r requirements.txt
Requirement already satisfied: pandas in /home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages (from -r requirements.txt (line 1)) (1.5.1)
ERROR: Could not find a version that satisfies the requirement torch==1.7.0 (from versions: 1.7.1, 1.8.0, 1.8.1, 1.9.0, 1.9.1, 1.10.0, 1.10.1, 1.10.2, 1.11.0, 1.12.0, 1.12.1, 1.13.0)
ERROR: No matching distribution found for torch==1.7.0
설치된 패키지 버전이 쫑난다는 얘기.
흠... 약간 이 리포가 만들어진지 2년이 지났고... 그 이후 업데이트가 거의 없었네...
KoBART 는 그나마 조금씩 업데이트 되었던 것 같아서 KoBART와 같은 버전을 쓰도록 살포시 바꿔줌.
pandas
torch==1.7.1
transformers==4.3.3
pytorch-lightning==1.2.1
streamlit==0.72.0
걱정되는 것이 1.7.1이 RTX3090을 지원 하는지...여부 인데...
일단 그건 나중에 걱정하고...
이제 학습을 위한 데이터를 준비하자.
리포에서 얘기한 말뭉치 데이터 링크는 끊겨 있어 다시 찾아 봄.
AI-Hub
www.aihub.or.kr
대충 이러하다.
데이터를 다운 받으려면 INNORIX Agent를 깔아야 하는데...
이 놈이 항상 상주하는 놈이라 영 찝찝하긴 하지만
깔아주자.
두 말뭉치 데이터를 다운 받고 압축을 풀어보면,
이렇게 생겼다.
(base) whyun@Mac-Studio 026.기술과학 분야 한-영 번역 병렬 말뭉치 데이터 % tree
.
└── 01.데이터
├── 1.Training
│ ├── 원천데이터
│ │ └── TS1.zip
│ └── 라벨링데이터
│ └── TL1.zip
└── 2.Validation
├── 원천데이터
│ └── VS1.zip
└── 라벨링데이터
└── VL1.zip
7 directories, 4 files(base) whyun@Mac-Studio 025.일상생활 및 구어체 한-영 번역 병렬 말뭉치 데이터 % tree
.
└── 01.데이터
├── 1.Training
│ ├── 원천데이터
│ │ ├── TS1.zip
│ │ └── TS2.zip
│ └── 라벨링데이터
│ ├── TL1.zip
│ └── TL2.zip
└── 2.Validation
├── 원천데이터
│ └── VS1.zip
└── 라벨링데이터
└── VL1.zip
7 directories, 6 files
참고로, AI허브에서 '활용 AI 모델 및 코드'도 같이 제공한다. 즉, 이 데이터를 이용해 학습된 모델을 제공하여 바로 사용할 수 도 있다. 도커 이미지로 제공되는데, inference 코드와 preTrained data는 추출이 가능하다. 다만, 아쉬운 것이 inference code만 있고 training code가 없으며... 학습할 때 iteration도 50번만 수행하였다.
50 epoch가 얼마나 대단한 것인지는 나중(이 글의 끝 부분 참고)에 알았다.
다만, 추가 데이터로 학습 시키거나 iteration을 더 돌려보려 해도 training code가 없어서 불가하다는 한계가 있다.
이 부분에 대해서 좀 더 파고 든 글은 다른 포스트로 올리겠음.
인공지능 신경망 설계하고 코딩해서 학습시켜 성능 검증하고 논문 쓴 다음에...
학습 코드는 일부러 빼고 공개하는 것이..
요즘 추세라고는 하더라..
기술과학분야 말뭉치를 보니...
특허 명세서에 있던 내용을 가져왔네..
바꿔 얘기하면..
실제 쓰이는 문장과는 거리가 멀다는 거... 데이터가 bias되어 있어 그다지 쓸모는 없을 것 같다..
특허 명세서의 문장은... 외계어라..
그래서.. 일상생활, 구어체 데이터만 학습시키기로 결정!
그러기 위해선,
KoBART-translation에서 사용하는 형태로 데이터를 변환해 주자
먼저, 파일을 열어보면..
"data": [
{
"sn": "ECOAR1A00003",
"data_set": "일상생활및구어체",
"domain": "해외고객과의채팅",
"subdomain": "숙박,음식점",
"en_original": "I'm glad to hear that, and I hope you do consider doing business with us.",
"en": "I'm glad to hear that, and I hope you do consider doing business with us.",
"mt": "그 소식을 들으니 기쁩니다. 우리와 거래하는 것을 고려해 보시기 바랍니다.",
"ko": "그 말을 들으니 기쁘고, 저희와 거래하는 것을 고려해 주셨으면 합니다.",
"source_language": "en",
"target_language": "ko",
"word_count_ko": 10.0,
"word_count_en": 15.0,
"word_ratio": 0.667,
"file_name": "해외고객과의채팅_숙박,음식점.xlsx",
"source": "크라우드 소싱",
"license": "open",
"style": "구어체",
"included_unknown_words": false,
"ner": null
},
...]이렇게 생긴게 1G 가량 있다.
장황하게 잡다한 데이터가 들어 있으나... 다 필요 없고... ko_original, en_orignial, ko, en, mt 등 만 잡아내면 되겠다.
mt는 기계 번역으로 나온 문장이고, en 또는 ko로 나온 것은 사람이 번역한 것으로 추정된다.
라벨링데이터 폴더에 있는 파일과 원천데이터에 있는 파일은 같은 내용을 담고 있다.
파일 하나만 보면 되겠다.
그런데, 한-영, 영-한 데이터셋은 완전히 따로 만들어진 것 같다. 그렇다는 얘기는 두 데이터 셋을 합칠 수도 있을 것 같다는 얘기..
KoBART-translate에 사용한 데이터 셋의 형태는 아래와 같다. 이에 맞춰 바꿔 보자.

한영 번역만 하게 하려면, 위 처럼 ko, en 으로 열을 맞춰주면 되고, 그 역의 경우라면 순서를 바꿔주면 될 문제라서 같은 데이터를 이용해 한-영, 영-한이 가능할 것 같다. 어쨌든 지금 하고 싶은건 한영번역이니....
import json
from tqdm import tqdm
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Argparse')
parser.add_argument('-t', '--type', type=str)
parser.add_argument('-i', '--input', type=str)
parser.add_argument('-o', '--output', type=str, default="output.tsv")
parser.add_argument('-m', '--mode', type=str, default="a")
args = parser.parse_args()
if(args.type is None):
print('Type is not specified ("e2k" or "k2e")')
exit(0)
with open(args.input, 'r') as ifp:
json_data = json.load(ifp)
input_data = json_data['data']
################################
# 이 방법도 되기는 하는데, 안 이뻐..
################################
# ofp = open(args.output, 'w')
# with tqdm(len(input_data)) as pbar:
# for index, value in enumerate(input_data):
# if(args.type == 'e2k'):
# ofp.write(f'{value["en"]}\t{value["mt"]}\n')
# ofp.write(f'{value["en"]}\t{value["ko"]}\n')
# elif(args.type == 'k2e'):
# ofp.write(f'{value["ko"]}\t{value["mt"]}\n')
# ofp.write(f'{value["ko"]}\t{value["en"]}\n')
# pbar.update(1)
# ofp.flush()
ofp = open(args.output, args.mode)
for value in tqdm(input_data):
if(args.type == 'e2k'):
if('en_original' in value):
ofp.write(f'{value["en"]}\t{value["mt"]}\n')
elif('ko_original' in value):
ofp.write(f'{value["mt"]}\t{value["ko"]}\n')
ofp.write(f'{value["en"]}\t{value["ko"]}\n')
elif(args.type == 'k2e'):
if('en_original' in value):
ofp.write(f'{value["mt"]}\t{value["en"]}\n')
elif('ko_original' in value):
ofp.write(f'{value["ko"]}\t{value["mt"]}\n')
ofp.write(f'{value["ko"]}\t{value["en"]}\n')
ofp.flush()
ofp.close()
이 내용대로 파일을 만들고.. 아래 명령으로 실행하면, e2k-train.tsv 파일과 e2k-test.tsv 파일이 만들어 짐.
python prep-data.py -t e2k -i ./01.데이터/1.Training/라벨링데이터/일상생활및구어체_영한_train_set.json -o e2k-train.tsv
python prep-data.py -t e2k -i ./01.데이터/2.Validation/라벨링데이터/VL1/일상생활및구어체_영한_valid_set.json -o e2k-test.tsv
python prep-data.py -t e2k -i ./01.데이터/1.Training/라벨링데이터/일상생활및구어체_한영_train_set.json -o e2k-train.tsv
python prep-data.py -t e2k -i ./01.데이터/2.Validation/라벨링데이터/VL1/일상생활및구어체_한영_valid_set.json -o e2k-test.tsv
k2e가 필요한 경우 적절히 파라미터 고쳐서 실행하면 됨.
이 파일들을 train.tsv, test.tsv로 만들어 ./data 디렉토리 밑으로 살포시 앉혀 놓는다.
조심스레... 흐트려지지 않도록..
자... 이제 준비는 끝났고..
학습 들어 간다.
KoBART-translation 리포에 나온대로 실행함.
python train.py --gradient_clip_val 1.0 --max_epochs 50 --default_root_dir logs --gpus 1 --batch_size 4
어라? 뭔가를 죽 다운로드 받네...
.cache/kobart_base_tokenizer_cased_cf74400bce.zip
이 파일의 내용은 아래와 같음.
(kobart) whyun@k8s-worker-node14:~/workspace/KoBART-translation$ ls -l .cache/kobart_from_pretrained/
total 483932
-rw-rw-r-- 1 whyun whyun 1089 Nov 5 21:04 config.json
-rw-rw-r-- 1 whyun whyun 495536138 Nov 5 21:04 pytorch_model.bin
KoBART를 다운 받은거지 translation 모델을 다운 받은 것은 아닌데..
그럼 아까 pip로 kobart 설치한 건 뭐지? 잘 동작은 했었는데..
아하.. 같은 파일이네.. 파일크기와 시간을 보니 한번 더 받았네.

그건 그렇고...
언제나 그러하듯, 한번에 될 리가 없지.
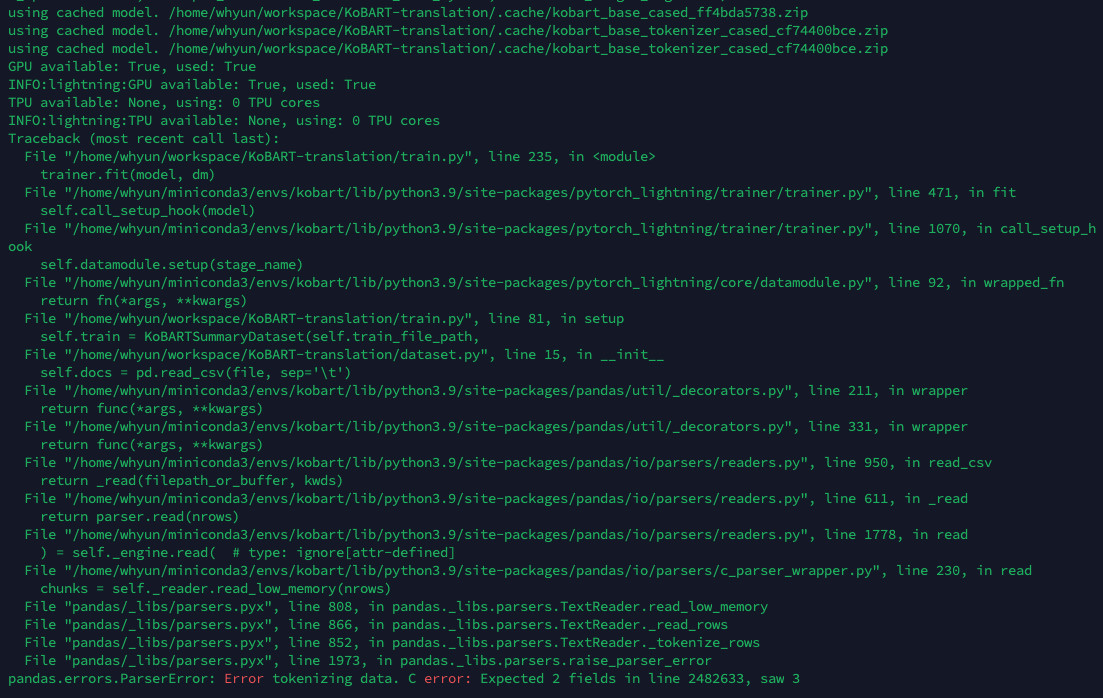
자...
지금부터 원인을 찾아 보자구!
input data 파일에서 읽어들이다가 2483633번째 라인에서 한 줄에 3개가 들어 왔다는 얘기네?
살펴보니 이상 없던데..? 어쨌든 고객님이 싫다니 해당 라인 없애고 다시 실행..
음? 이제 2482631 라인에서 문제가 있다고?
흠... 고갱님?
엑셀로 불러들여 함 열어봄. 진짜 잘 못된 것이라면 컬럼이 3개가 있어야 하겠지..
못 여네..
아래처럼 문제 있는 라인은 스킵하도록 수정함. (dataset.py)
data = pd.read_csv("file1.csv", error_bad_lines=False)
대략 10개 정도의 데이터가 오류가 있다고 나오는데.. 무시하고 넘어가고 계속 실행 함.
역시나..
뭔가 찜짐한 것은 꼭 문제를 일으키지..
INFO:pytorch_lightning.accelerators.gpu:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/cuda/__init__.py:104: UserWarning:
NVIDIA GeForce RTX 3090 with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70 sm_75.
If you want to use the NVIDIA GeForce RTX 3090 GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
pyTorch 1.7.1 은 3090 아키텍처를 지원하지 못해..
업데이트 해야지 머.. 내가 힘 있간?
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116업데이트 해 줌.
2기가 조금 넘게 다시 받음.
다만 아래와 같은 에러가 뿜뿜.
Requirement already satisfied: idna<4,>=2.5 in /home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages (from requests->torchvision) (3.4)
Installing collected packages: torch, torchvision, torchaudio
Attempting uninstall: torch
Found existing installation: torch 1.7.1
Uninstalling torch-1.7.1:
Successfully uninstalled torch-1.7.1
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
kobart 0.5.1 requires torch==1.7.1, but you have torch 1.13.0+cu116 which is incompatible.
뭐.. 어쩌갔어. 가는그야!

--== 쉬는 시간 ==---
다시 실행시키니, pandas 쪽에서 critical error를 내면서 죽음.
INFO:root:number of workers 1, data length 4793704
INFO:root:num_train_steps : 59921300
INFO:root:num_warmup_steps : 5992130
| Name | Type | Params
-------------------------------------------------------
0 | model | BartForConditionalGeneration | 123 M
-------------------------------------------------------
123 M Trainable params
0 Non-trainable params
123 M Total params
495.440 Total estimated model params size (MB)
INFO:lightning:
| Name | Type | Params
-------------------------------------------------------
0 | model | BartForConditionalGeneration | 123 M
-------------------------------------------------------
123 M Trainable params
0 Non-trainable params
123 M Total params
495.440 Total estimated model params size (MB)
Validation sanity check: 0%| | 0/2 [00:00<?, ?it/s]Traceback (most recent call last):
File "/home/whyun/workspace/KoBART-translation/train.py", line 235, in <module>
trainer.fit(model, dm)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 513, in fit
self.dispatch()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 553, in dispatch
self.accelerator.start_training(self)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/accelerators/accelerator.py", line 74, in start_training
self.training_type_plugin.start_training(trainer)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/plugins/training_type/training_type_plugin.py", line 111, in start_training
self._results = trainer.run_train()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 614, in run_train
self.run_sanity_check(self.lightning_module)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 863, in run_sanity_check
_, eval_results = self.run_evaluation(max_batches=self.num_sanity_val_batches)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 719, in run_evaluation
for batch_idx, batch in enumerate(dataloader):
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 1085, in _next_data
return self._process_data(data)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 1111, in _process_data
data.reraise()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/_utils.py", line 428, in reraise
raise self.exc_type(msg)
KeyError: Caught KeyError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pandas/core/indexes/base.py", line 3803, in get_loc
return self._engine.get_loc(casted_key)
File "pandas/_libs/index.pyx", line 138, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/index.pyx", line 165, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/hashtable_class_helper.pxi", line 5745, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas/_libs/hashtable_class_helper.pxi", line 5753, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 'kr'
데이터에서 'kr' 키워드가 없다는 얘기인데.. 혹시... 헤더(맨 첫줄)에 'kr','en' 없어서?
에이 설마..
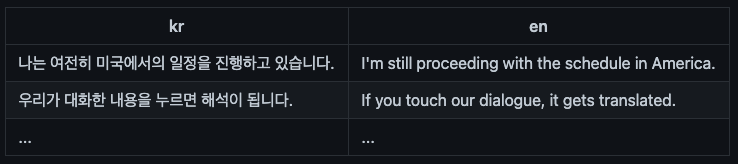
혹시 몰라 제일 첫 줄에 en, kr을 넣어 줌. --> P.R.O.F.I.T!!
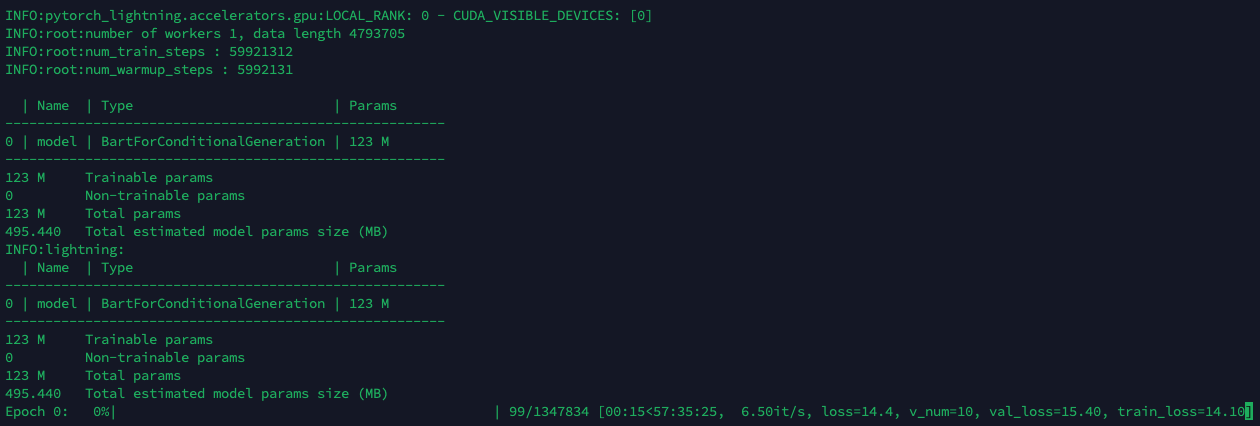
CUDA를 못 찾는 것 같아 확인해 보니, 잘 사용하고 있음.
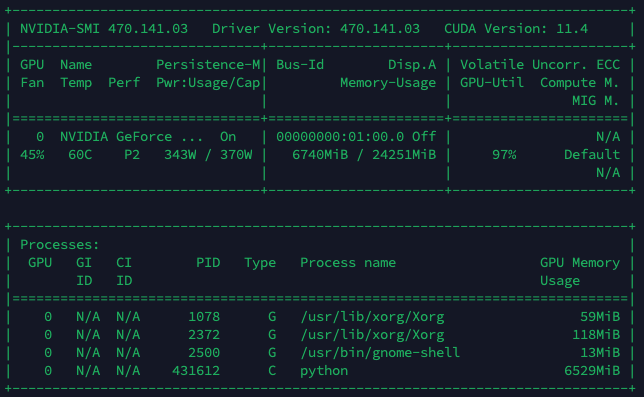
CPU 도... 메모리도 낭낭하게 처묵..처묵...
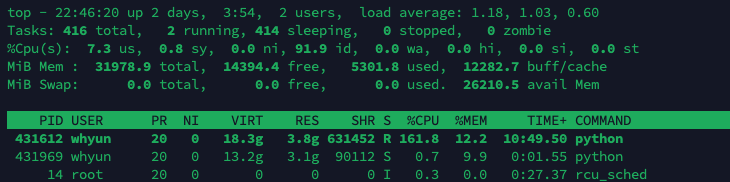
이제 기다리면 되는데....
언제까지?
저 화면 상으로는.... 한 epoch 돌리는데 57시간... 50 epoch이면...
57/24*50=네 달?
그건 아니지 싶어.. batch 크기를 4에서 8로 늘려 봄. GPU 메모리가 아직 여유 있으니까 늘려봄.

오호라... 50시간으로 주네?
흠... GPU 메모리도.. 1G만 쳐묵쳐묵 해서.. 아직 여유가 있네?
그럼 더 늘리는거지... 8에서 16으로 가즈아~!!

흠... 46시간이 최대인가 보다..
그럼... 100일쯤... 세달..
음... 24로 올리면 어떨까? 간당간당하긴 한데... 44시간 50분까지는 단축할 수 있긴 하네..
44.8/24*50 = 93일... 세달...
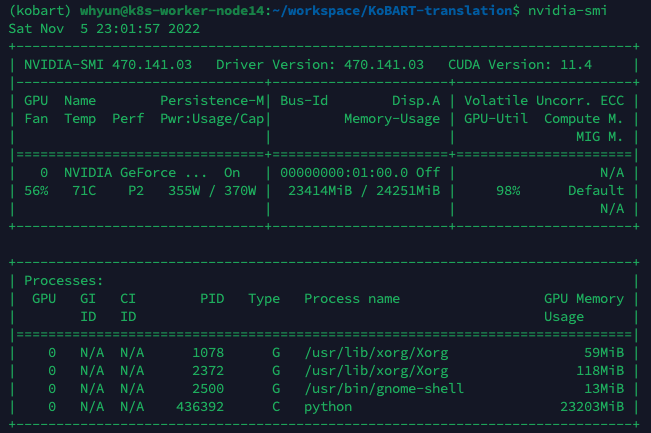
짱짱한 GPU 쓰는데도 그다지 빠르진 않구나...
어.. 잠깐..
내가 필요한 건 영-한 번역인데...
나 뭐한거임?
끗.
인 줄 알았으나...
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/utilities/apply_func.py", line 81, in apply_to_collection
return function(data, *args, **kwargs)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 628, in __next__
data = self._next_data()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 1333, in _next_data
return self._process_data(data)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 1359, in _process_data
data.reraise()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/_utils.py", line 543, in reraise
raise exception
TypeError: Caught TypeError in DataLoader worker process 4.
Original Traceback (most recent call last):
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/_utils/worker.py", line 302, in _worker_loop
data = fetcher.fetch(index)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/_utils/fetch.py", line 58, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/torch/utils/data/_utils/fetch.py", line 58, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/whyun/workspace/KoBART-translation/dataset.py", line 40, in __getitem__
input_ids = self.tok.encode(instance['kr'])
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/transformers/tokenization_utils_base.py", line 2104, in encode
encoded_inputs = self.encode_plus(
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/transformers/tokenization_utils_base.py", line 2420, in encode_plus
return self._encode_plus(
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/transformers/tokenization_utils_fast.py", line 455, in _encode_plus
batched_output = self._batch_encode_plus(
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/transformers/tokenization_utils_fast.py", line 382, in _batch_encode_plus
encodings = self._tokenizer.encode_batch(
TypeError: TextEncodeInput must be Union[TextInputSequence, Tuple[InputSequence, InputSequence]]
아.... 이건 또 무슨 에러인가요?
바로 죽었으면 원인을 찾았지...
몇 시간 돌다 죽으면 어떻하니..
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/whyun/workspace/KoBART-translation/train.py", line 235, in <module>
trainer.fit(model, dm)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 513, in fit
self.dispatch()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 553, in dispatch
self.accelerator.start_training(self)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/accelerators/accelerator.py", line 74, in start_training
self.training_type_plugin.start_training(trainer)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/plugins/training_type/training_type_plugin.py", line 111, in start_training
self._results = trainer.run_train()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 676, in run_train
self.train_loop.on_train_end()
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/training_loop.py", line 134, in on_train_end
self.check_checkpoint_callback(should_update=True, is_last=True)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/trainer/training_loop.py", line 164, in check_checkpoint_callback
cb.on_validation_end(self.trainer, model)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/callbacks/model_checkpoint.py", line 212, in on_validation_end
self.save_checkpoint(trainer, pl_module)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/callbacks/model_checkpoint.py", line 247, in save_checkpoint
self._validate_monitor_key(trainer)
File "/home/whyun/miniconda3/envs/kobart/lib/python3.9/site-packages/pytorch_lightning/callbacks/model_checkpoint.py", line 490, in _validate_monitor_key
raise MisconfigurationException(m)
pytorch_lightning.utilities.exceptions.MisconfigurationException: ModelCheckpoint(monitor='val_loss') not found in the returned metrics: ['train_loss']. HINT: Did you call self.log('val_loss', tensor) in the LightningModule?
Epoch 0: 3%|▎ | 6833/224640 [1:21:46<43:26:28, 1.39it/s, loss=2.87, v_num=14, val_loss=15.60, train_loss=2.920]
또 하나가... 체크포인트 저장하다가 에러가 생기셨네요..
Misconfiguration 에러면... 흠...
차근차근 또 잡아 봅시다.
일단
"TypeError: TextEncodeInput must be Union[TextInputSequence, Tuple[InputSequence, InputSequence]]" 에러는 입력 데이터의 결측치 때문이라고 하는데.. 이건 입력단계에서 걸러졌어야 할 것 같은데.. 아마 초기 데이터 불러 들일때 error 발생시 그냥 넘어가게 한 것 때문인 것 같다. 문제가 있는 데이터를 버린 것이 아니라 그대로 읽어들인게 아닌가 싶다.
[DL] TypeError: TextEncodeInput must be Union[TextInputSequence, Tuple[InputSequence, InputSequence]]
학습이 잘 돌아가던 중 1epoch가 달성되기 전에 갑자기 아래와 같은 에러가 발생했다. TypeError: TextEncodeInput must be Union[TextInputSequence, Tuple[InputSequence, InputSequence]] 원인은 Text data에서 Tokenizing할때 결
bslife.tistory.com
https://cosmosproject.tistory.com/308
Python Pandas : dropna (NaN value가 있는 row/column 제거하기)
dropna function은 DataFrame에서 NaN value가 존재하는 행(row) 또는 열(column)을 제거해줍니다. dropna의 syntax는 다음과 같습니다. DataFrame.dropna(axis=0/1, how='any'/'all', subset=[col1, col2, ...], inplace=True/False) dropna에
cosmosproject.tistory.com
dataset.py에서 dropna(axis=0, inplace=True) 를 추가하여 결측치를 제거하도록 하였다.
self.docs.dropna(axis=0, inplace=True)
그리고, 데이터 셋을 훈련용 1000개, 테스트용 200개만 잘라서 돌려 보았다.
잘 돌아간다. 체크포인트 저장도 문제가 없이 진행된다. 아마 입력 데이터의 문제였나 보다.
그냥 호기심에 15 에폭 돌리다가 죽인 후 다시 돌렸더니... 마지막 부터 시작하지 않고 다시 처음부터 한다.
체크포인트 파일의 크기가 1.4G쯤 된다. 매 에폭마다 생성된다.
다시 풀셋 데이터로 돌려보자.
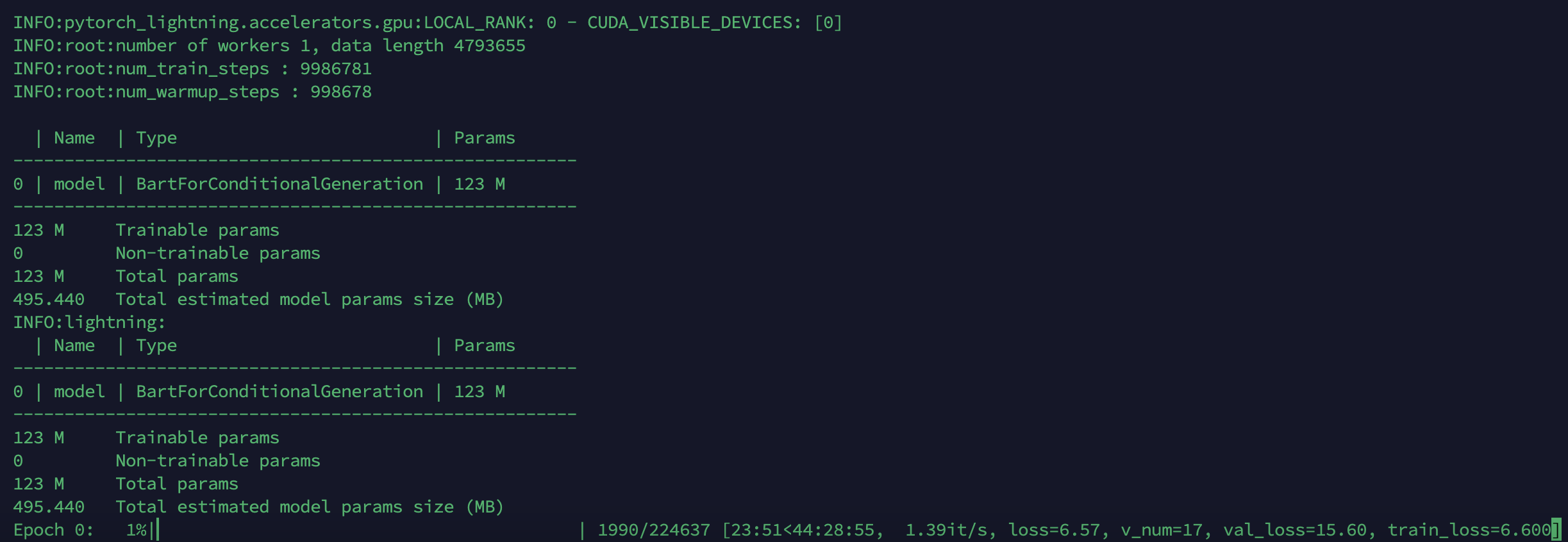
dropna를 하고 난 이후 전체 데이터셋의 개수가 대폭 줄었다.
batch의 수가 336959에서 224637개로.. 줄었으니... 11만 x 24 문장이 날라간건가?
그런데 시간은 줄지 않았네..
batch가 그 의미는 아닐라나..
다시 기다림의 시간으로..
'인공지능' 카테고리의 다른 글
| HuggingFace로 Stable Diffusion 사용하기 (0) | 2022.11.06 |
|---|---|
| [찍먹분투기] AI Hub 일상생활 및 구어체 한-영 번역 말뭉치 데이터 AI 모델 분석 (0) | 2022.11.06 |
| [요약] 농업분야에서 실제 인공지능 활용 가능 분야 (0) | 2022.11.06 |
| [오픈소스] 실시간 목소리 복제 (0) | 2022.11.05 |
| [오픈소스] 사람 몸짓을 복사해주는 인공지능 (Liquid Warping GAN w. attention) (0) | 2022.11.05 |
